1. Perceptron
binary classification을 위한 supervised learning 알고리즘으로, 최근에는 single layer보다 좀 더 복잡한 neural network(multi layer)를 구성하여 deep leaning에서 활용하고 있다.

- Input layer
- Weights
- Bias
복잡한 패턴을 모델링하는데 있어 유연성을 주기 위해 Input layer에 추가하는 data - Activation function
Input과 bias로 weighted sum하여 output을 결정한다. 주로 sigmoid, ReLu 등 니즈에 맞게 function을 선택하여 사용한다.
- Output
Binary값으로 1 또는 0으로 perceptron의 결과가 나온다. - Training algorithm
perceptron은 supervised learning이기 때문에 학습(train)이 필요하다. 학습을 통해 weight과 bias가 실제 값과 모델의 결과 사이의 차이(error)를 최소화 한다. 주로 backpropagation(chain rule)을 통한 gradient descent(경사하강법)을 사용한다.
2. Training Algorithm
Gradient Descent
"왜 gradient descent를 쓰는지" 를 알려면 수학적인 접근이 필요하다.
- 실제 값과 모델의 결과 사이의 차이를 구하기 위해 행렬(matrix)로 표현하고 이를 최소화하기 위해 미분을 한다(Ordinary Least Squres).
- 이 때, matrix의 역행렬(inverse)을 구해야하는데, complexity가 높아지는 문제가 발생하여 이를 대체하는 방법으로 gradient descent를 사용한다(자세한 것은 생략).
Gradient descent는 말 그대로 학습 도중 업데이트 된 weight, bias (parameters)를 통해 줄어든 error의 경사를 구하고, 경사가 최소가 되는 지점(convergence)을 찾는 과정이다. 경사를 학습시 업데이트 하는 parameter의 폭을 learning rate라고 하는데,
- learning rate이 너무 작으면, 학습하는데 시간이 너무 오래 걸리게 되고
- learning rate가 너무 크면, 최소점을 벗어나 최적화를 시키지 못할 수 있다(overshooting).
Stochastic Gradient Descent (SGD)
Gradient descent는 모든 데이터를 전부 계산하여 weight와 bias를 업데이트하기 때문에 느리다는 단점이 있다.
θ=θ−▽θJ(θ)
▽θ : cost function 기울기
J(θ) : cost function
이를 해결하기 위해 각 iteration마다 1개의 데이터만을 사용하여 weight와 bias를 업데이트 한다면 (batch) gradient descent보다는 부정확하지만 빠르게 학습할 수 있다. 이를 stochastic gradient descent (SGD)라고 한다.
θ=θ−η⋅▽θJ(θ;x(i:i+n);y(i:i+n)
η : Learning rate
SGD보다 더 좋은 방법 제안
Gradient Descent에는 Non-convex 오차를 가진 함수에서 말 안장 형태 (saddle point)를 가진 경우, 최소점을 구하기 어렵다는 한계가 있음.
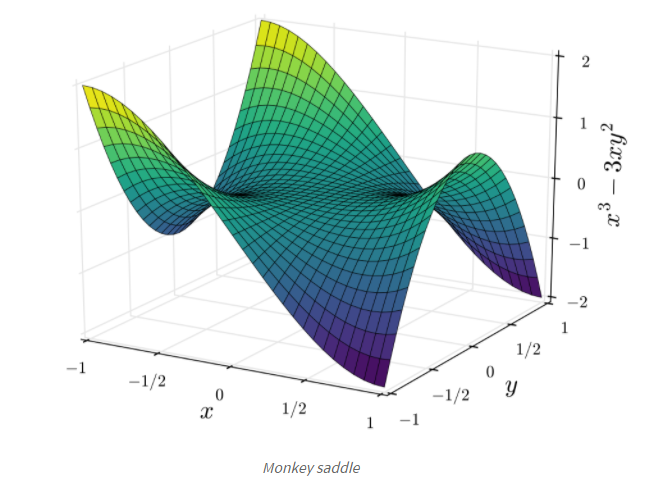
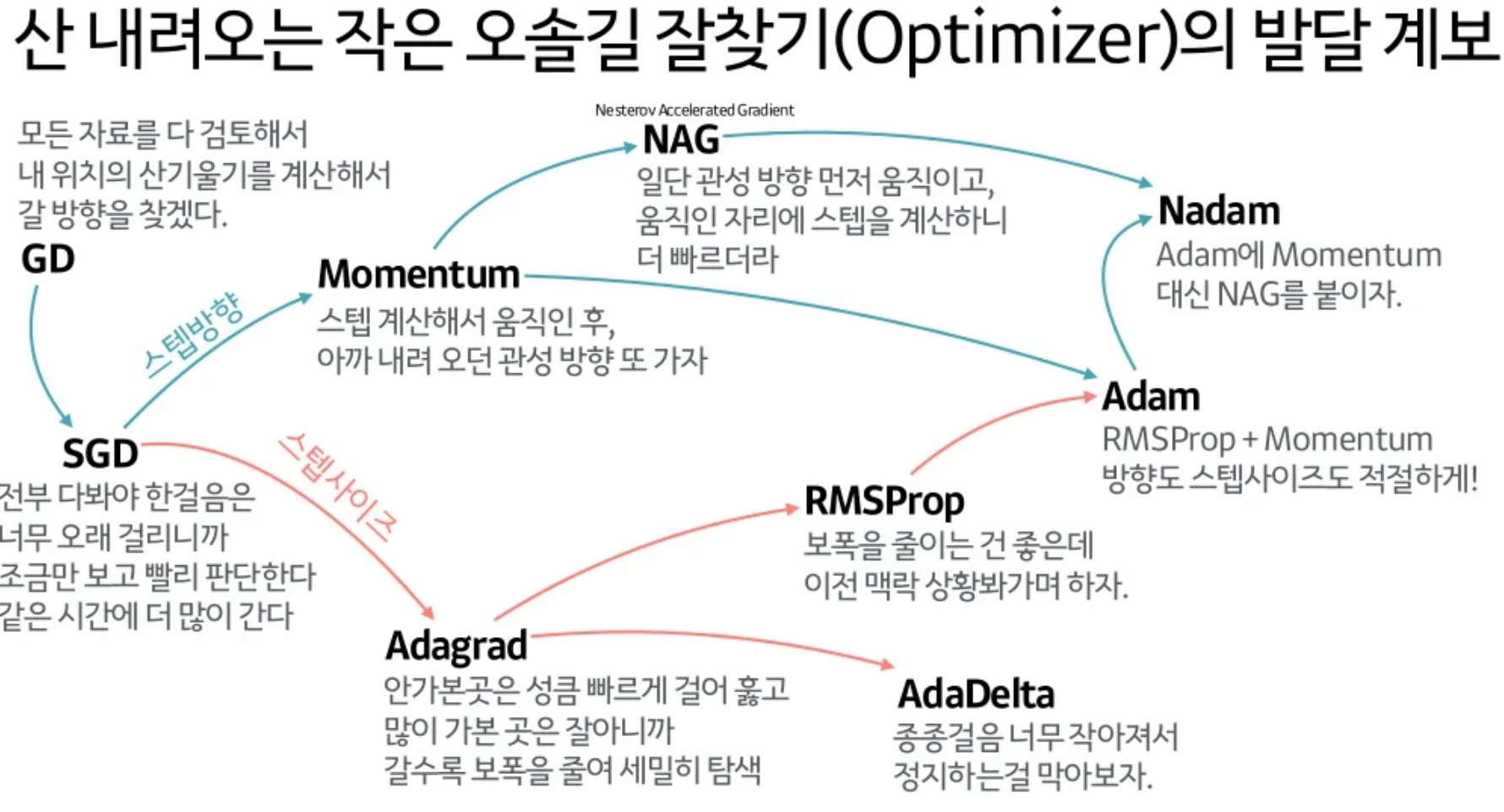
그 밖에 학습 결과에 대한 평가 및 그에 대한 해결책은 아래 포스팅에서 추가로 확인 가능
딥러닝 기초 - Underfitting, Overfitting
DNN (Deep Neural Network) 란? Neural Network에서 hidden layer가 2개 이상인 경우 (hidden layer가 점점 많아지면) DNN이라고 합니다. 사람의 뇌를 닮아서 사람이 할 수 있는걸 전부 할 수 있는 것 같지만 문제점이
seulkom.tistory.com
References
https://sebastianraschka.com/faq/docs/activation-functions.html
Activation Functions for Artificial Neural Networks
sebastianraschka.com
https://www.kdnuggets.com/2020/05/5-concepts-gradient-descent-cost-function.html
5 Concepts You Should Know About Gradient Descent and Cost Function - KDnuggets
Why is Gradient Descent so important in Machine Learning? Learn more about this iterative optimization algorithm and how it is used to minimize a loss function.
www.kdnuggets.com
https://towardsdatascience.com/an-introduction-to-gradient-descent-c9cca5739307
An Introduction to Gradient Descent
This blog will cover following questions and topics:
towardsdatascience.com
https://www.slideshare.net/yongho/ss-79607172
자습해도 모르겠던 딥러닝, 머리속에 인스톨 시켜드립니다.
자습해도 모르겠던 딥러닝, 머리속에 인스톨 시켜드립니다. - Download as a PDF or view online for free
www.slideshare.net
'Study > Data Science' 카테고리의 다른 글
| 딥러닝 기초 - Underfitting, Overfitting (0) | 2022.03.21 |
|---|---|
| Hadoop 개요 및 Hadoop 2.0 의 방향 (0) | 2017.09.27 |
| 린 분석 [#1] 좋은 지표를 찾는 방법 (0) | 2016.12.14 |


